TimeXer(NeurIPS, 2024)
TimeXer(NeurIPS, 2024)
源代码
由于真实世界中时间序列预测的部分观察的特性,完全关注 内生性变量 (Endogenous, 即关注的目标变量) 是不足以保证预测的准确性。外生性变量(Exogenous, 即非关注的目标变量) 也会为模型提供宝贵的外部信息。因此,相较于之前的模型仅关注目标变量或者将所有变量相同对待的情况,这边文章提出了模型 TimeXer 来处理外部信息以预测内生性变量。
Introduction
从时间序列建模的角度来看,外生性变量是作为预测的辅助信息而不需要被预测,其与内生性变量的不同给目前已有模型提出了新的挑战:首先,对于具有多个外部变量的模型,模型需要去权衡不同变量之间的依赖性与差异性,如果简单让外生性变量和内生性变量等价,则会造成不必要的交互;第二,外部变量可能存在与内生性变量的因果关系,所以模型也要能处理系统上的时间延迟现象;另外,一个实际使用的时间序列模型应该能够处理非规则的、具有异质性的时间序列,包括缺失值、时间未对齐、频率不匹配、长度差异。
TimeXer
Problem Setting
在具有外生性变量的预测中,我们被给予了一个时间序列 $\mathbf{x}_{1:T}={ x_{1},x_{2},\dots,x_{T} }\in \mathbb{R}^{T\times 1}$ 与多个外生性时间序列 $\mathbf{z}_{1:T_{ex}}={ \mathbf{z}_{1:T_{ex}}^{(1)},\mathbf{z}_{1:T_{ex}}^{(2)}, \dots,\mathbf{z}_{1:T_{ex}}^{(C)} }\in \mathbb{R}^{T_{ex}\times C}$. 此处 $x_{i}$ 代表第 i 个时间点, $\mathbf{z}_{1:T_{ex}}^{(i)}$ 代表第 i 个外生性变量,C 为外生性变量的数目。另外,$T, T_{ex}$ 为回看窗口长度,分别为内生性和外生性变量的回看长度。此处,为了能够满足不等长的情况,作者直接采用了最普适的情况,即 $T \neq T_{ex}$ , 综上,模型预测未来 S 个点的目标可以被如下公式化:
$$
\hat{\mathbf{x}}_{T+1:T+S}=\mathcal{F}_{\theta}(\mathbf{x}_{1:T},\mathbf{z}_{1:T_{ex}})
$$
Structure Overview
如下图所示,TimeXer 重新利用了传统的 Transformer 架构,内生性变量与外生性变量的处理是通过不同的嵌入策略,而 TimeXer 只是使用了 自注意力(Self-attention) 和 交叉注意力(Cross-attention) 机制来分别捕捉时间和变量上的依赖性。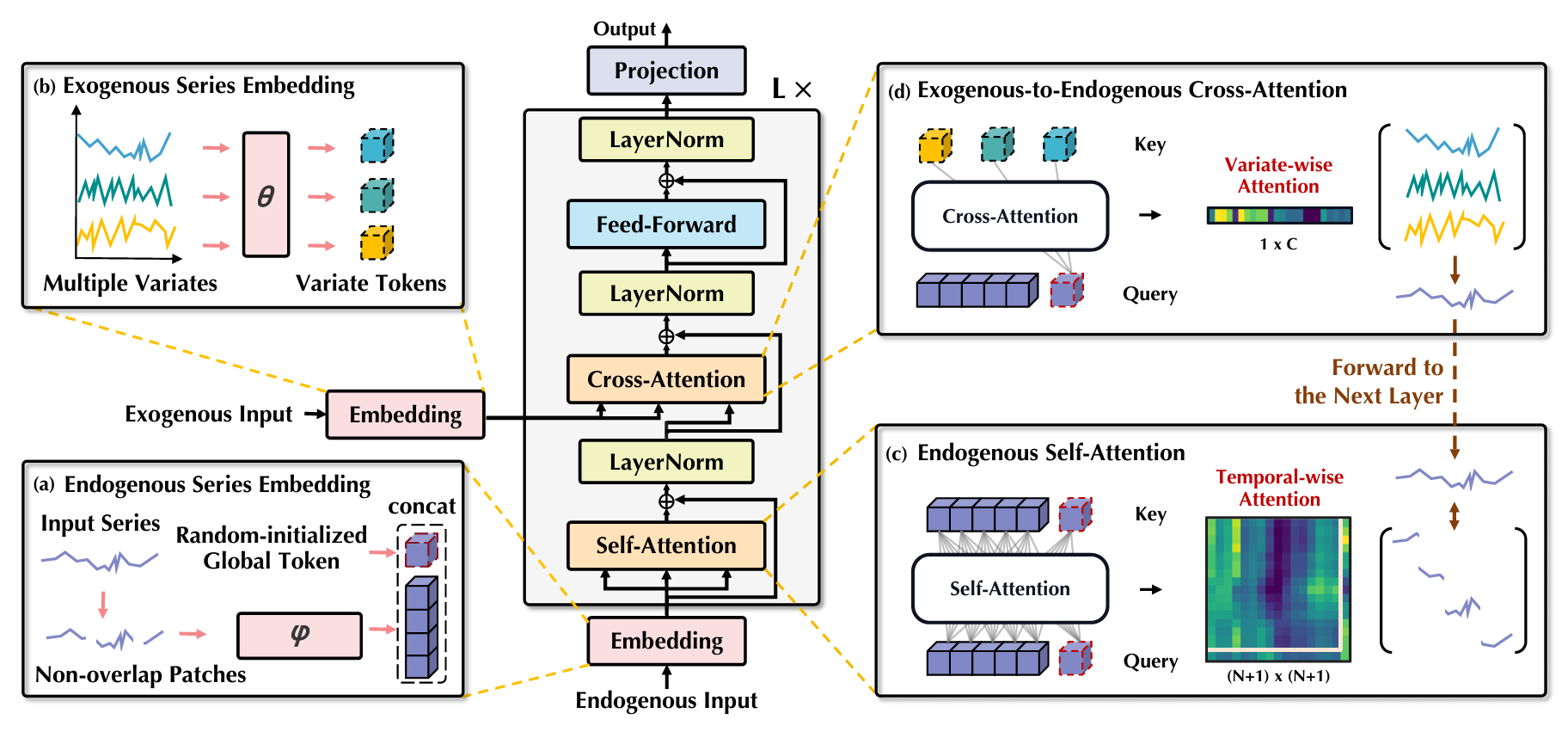
内生性嵌入
大部分已有的基于Transformer预测模型将每个时间点或者时间片段嵌入为一个时间token并使用自注意力机制来学习时间相关性。为了捕捉内生性变量时间维度上的变化,TimeXer 使用了 patch-wise 的表示,具体来说,内生性时间序列被分为多个无交叉的 patches,每个patch被映射为一个时间token,考虑到内生性变量与外生性变量在预测过程中的不同作用,模型在嵌入的过程中采用了不同的颗粒度。因此,直接将不同颗粒度的变量混合会造成信息未对齐。为了解决这个问题,作者为每个内生性变量引入了一个可学习的全局 token ,这个 token 作为宏观表示用于与外生性变量交互。这样的设计实现了从外生性变量向内生性变量的因果信息的流动,也就是应用了外生性变量对于内生性变量的因果关系。内生性嵌入可以如下表示:
$$
\begin{align*}
{\mathbf{s}_1, \mathbf{s}_2, …, \mathbf{s}_N} &= \text{Patchify}\left(\mathbf{x}\right), \\
\mathbf{P}_{\text{en}} &= \text{PatchEmbed}\left(\mathbf{s}_1, \mathbf{s}_2, …, \mathbf{s}_N\right), \\
\mathbf{G}_{\text{en}} &= \text{Learnable}\left(\mathbf{x}\right).
\end{align*}
$$
其中 P 为 patch 的长度,$N=\left\lfloor \frac{T}{P} \right\rfloor$ 为 patch 的数目。$\text{PatchEmbed}$ 将每个长度为 P 的patch通过加上位置编码嵌入为一个 D 维的向量,嵌入使用可训练线性层。总之,N个patch级别的时间token嵌入 $\mathbf{P}_{\text{en}}$ 和 1 个序列级别的全局 token 嵌入 $\mathbf{G}_{\text{en}}$ 被输入至 Transformer 编码器。
外生性嵌入
作者选择进行变量级别的表示,这是由于外生性变量常存在缺失值、不对齐、频率不同的情况。如果采用 patch级别的表示,则表示过于细粒度,这不仅仅带来高计算复杂度,同时也带来了无必要的噪声。于是作者如下对于每个外生性序列进行序列级别的变量嵌入:
$$
\mathbf{V}_{\text{ex},i}=\text{VariateEmbed}(\mathbf{z}^{(i)}),i\in { 1,\dots,C }
$$
这里的 $\text{VariateEmbed}: \mathbb{R}^{T_{\text{ex}}}\to \mathbb{R}^D$ 是一个可训练的线性预测器, $T_{\text{ex}}$ 是回看的长度。$\mathbf{V}_{\text{ex}}={ \mathbf{V_{\text{ex}}}_{,i} }_{i=1}^C$ 为多个外生性变量序列的表示集合。
内生性变量的自注意力机制
- Patch-to-Global: 全局token关注时间token来集成全序列的patch级别的信息。
- Global-to-Patch: 每个时间token关注全局token来获得变量级别的相关性。这提供了内生性变量内部的时间依赖性。
- Patch-to-Patch: 内生性变量的Patch之间进行交互。
$$
\begin{align*}
\text{Patch-to-Patch: } & \widehat{\mathbf{P}}_{\text{en}}^{l,1} = \text{LayerNorm} \left( \mathbf{P}_{\text{en}}^{l} + \text{Self-Attention} \left( \mathbf{P}_{\text{en}}^{l} \right) \right), \\
\text{Global-to-Patch: } & \widehat{\mathbf{P}}_{\text{en}}^{l,2} = \text{LayerNorm} \left( \mathbf{P}_{\text{en}}^{l} + \text{Cross-Attention} \left( \mathbf{P}_{\text{en}}^{l}, \mathbf{G}_{\text{en}}^{l} \right) \right) \\
\text{Patch-to-Global: } & \widehat{\mathbf{G}}_{\text{en}}^{l} = \text{LayerNorm} \left( \mathbf{G}_{\text{en}}^{l} + \text{Cross-Attention} \left( \mathbf{G}_{\text{en}}^{l}, \mathbf{P}_{\text{en}}^{l} \right) \right)
\end{align*}
$$
总体的过程可以简化为一个内部变量的自注意力计算
$$
\widehat{\mathbf{P}}_{\text{en}}^l, \widehat{\mathbf{G}}_{\text{en}}^l = \text{LayerNorm} \left( [\mathbf{P}_{\text{en}}^l, \mathbf{G}_{\text{en}}^l] + \text{Self-Attention} \left( [\mathbf{P}_{\text{en}}^l, \mathbf{G}_{\text{en}}^l] \right) \right)
$$
其中 $l\in { 0,\dots,L-1 }$ 记为 第 l 层 TimeXer 块,且 $\mathbf{P}_{\text{en}}^0=\mathbf{P}_{\text{en}}, \mathbf{G}_{\text{en}}^0=\mathbf{G}_{\text{en}}$。这里的 $[\cdot,\cdot]$ 为 patch-级别tokens与全局token在序列维度上的堆叠(concat)。通过在堆叠得到的矩阵上使用一个自注意力层,TimeXer 可以捕捉到patches之间的时间依赖性与patches和全序列之间的关系。
Exo-to-Endo Cross-Attention
交叉注意力机制被常常用于多模态学习中,用于适应性捕捉不同模态间 token 级别的依赖性。在 TimeXer 中,交叉注意力将内生性变量作为 query,外生性变量作为 key 和 value 来构造这两类变量之间的链接。既然外生性变量被嵌入为变量级别的tokens,作者使用学到的内生性变量全局token来集成外生性变量中的信息。这个过程可以如下公式化:
$$
\text{Variate-to-Global: } \widehat{\mathbf{G}}_{\text{en}}^l = \text{LayerNorm} \left( \widehat{\mathbf{G}}_{\text{en}}^l + \text{Cross-Attention} \left( \widehat{\mathbf{G}}_{\text{en}}^l, \mathbf{V}_{\text{ex}} \right) \right)
$$
最终,所有的时间tokens和可学习全局token都会被前馈层转化:
$$
\mathbf{P}_{\text{en}}^{l+1} = \text{Feed-Forward} \left( \widehat{\mathbf{P}}_{\text{en}}^{l} \right), \mathbf{G}_{\text{en}}^{l+1} = \text{Feed-Forward} \left( \widehat{\mathbf{G}}_{\text{en}}^{l} \right)
$$
其中 $l\in { 1,\dots,L }$,我们可以将 Transformer 块写为如下 $\mathbf{P}_{\text{en}}^{l+1},\mathbf{G}_{\text{en}}^{l+1}=\text{TrmBlock}(\mathbf{P}_{\text{en}}^{l},\mathbf{G}_{\text{en}}^{l})$
Forcasting Loss
对于最终输出 $[\mathbf{P}_{\text{en}}^L,\mathbf{G}_{\text{en}}^L]$ 使用一个线性层映射为 $\hat{\mathbf{x}}$ .并使用平方误差(L2误差)来作为Loss。


